PEAR27

pear27's coding record
Send Me an Email
jinalks43@gmail.com
View My GitHub Profile
https://github.com/pear27
웹 사이트 크롤링: 이벤트 페이지 가져오기
by pear27
사용자의 보유 카드 혜택 기반 추천을 위해, 가장 먼저 카드사 홈페이지에서 제공하는 카드 혜택 정보를 크롤링하여 가져오는 로직을 작성해야 합니다.
하나, 현대, 국민, 롯데, 삼성, 신한 등 6개 카드사의 카드 혜택 정보는 2024년에 학교 선배님께서 작성하신 코드를 fork하여 필요한 부분을 수정하는 방식으로 진행할 수 있었으나 (하지만 여기도 결국 코드를 갈아엎어야 했다..), 이번 프로젝트에서 우리 팀이 추가하기로 한 카드사별 기간 한정 이벤트 정보는 코드를 아예 새로 짜야 했습니다.
본 포스트는 KB국민카드의 KB이벤트 화면의 크롤링 코드 작성 과정을 다루고 있습니다.
페이지 구조 살펴보기
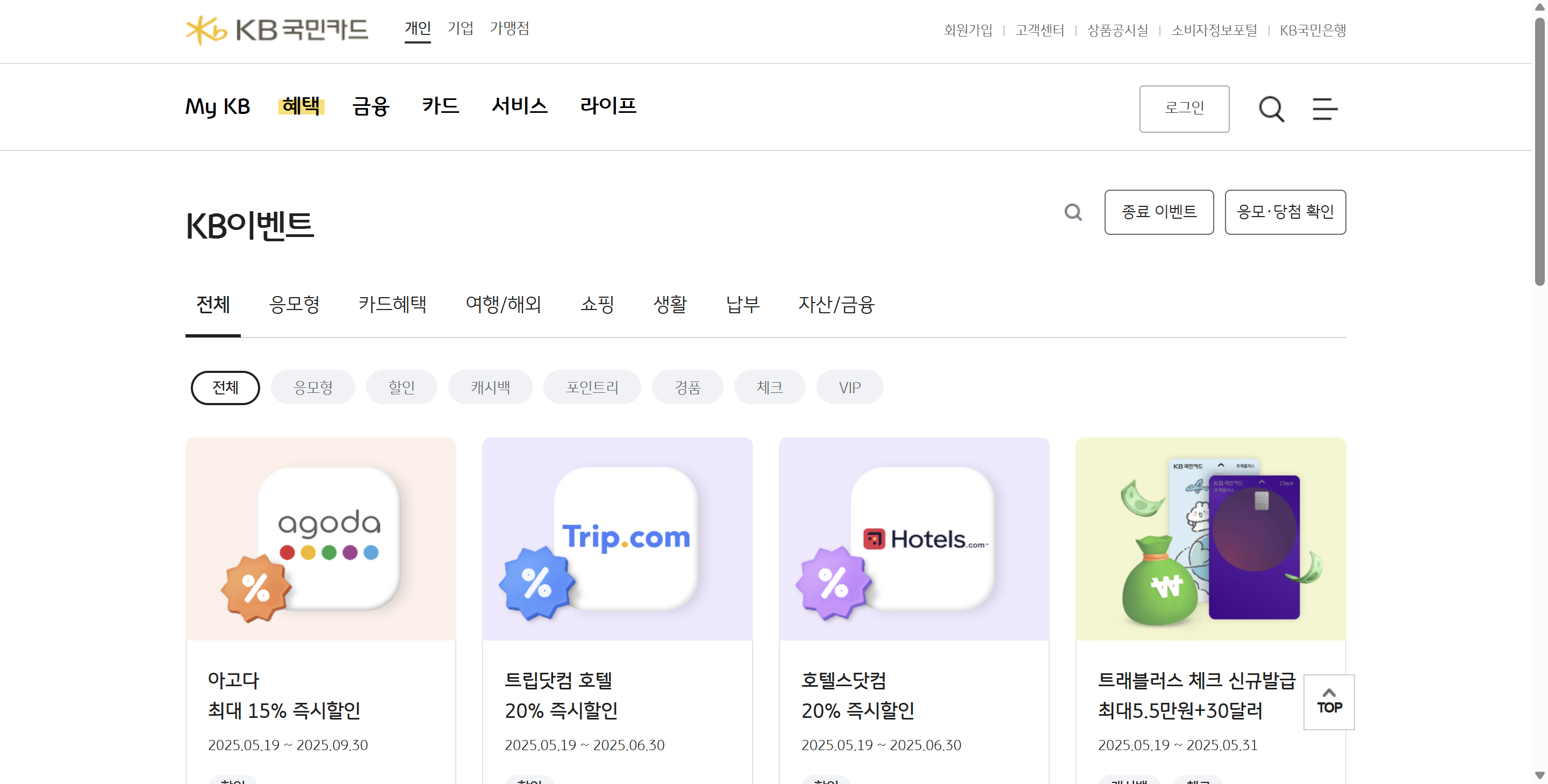
크롤링할 페이지는 위와 같이 여러 개의 element가 grid 형태로 배치되어 있고,
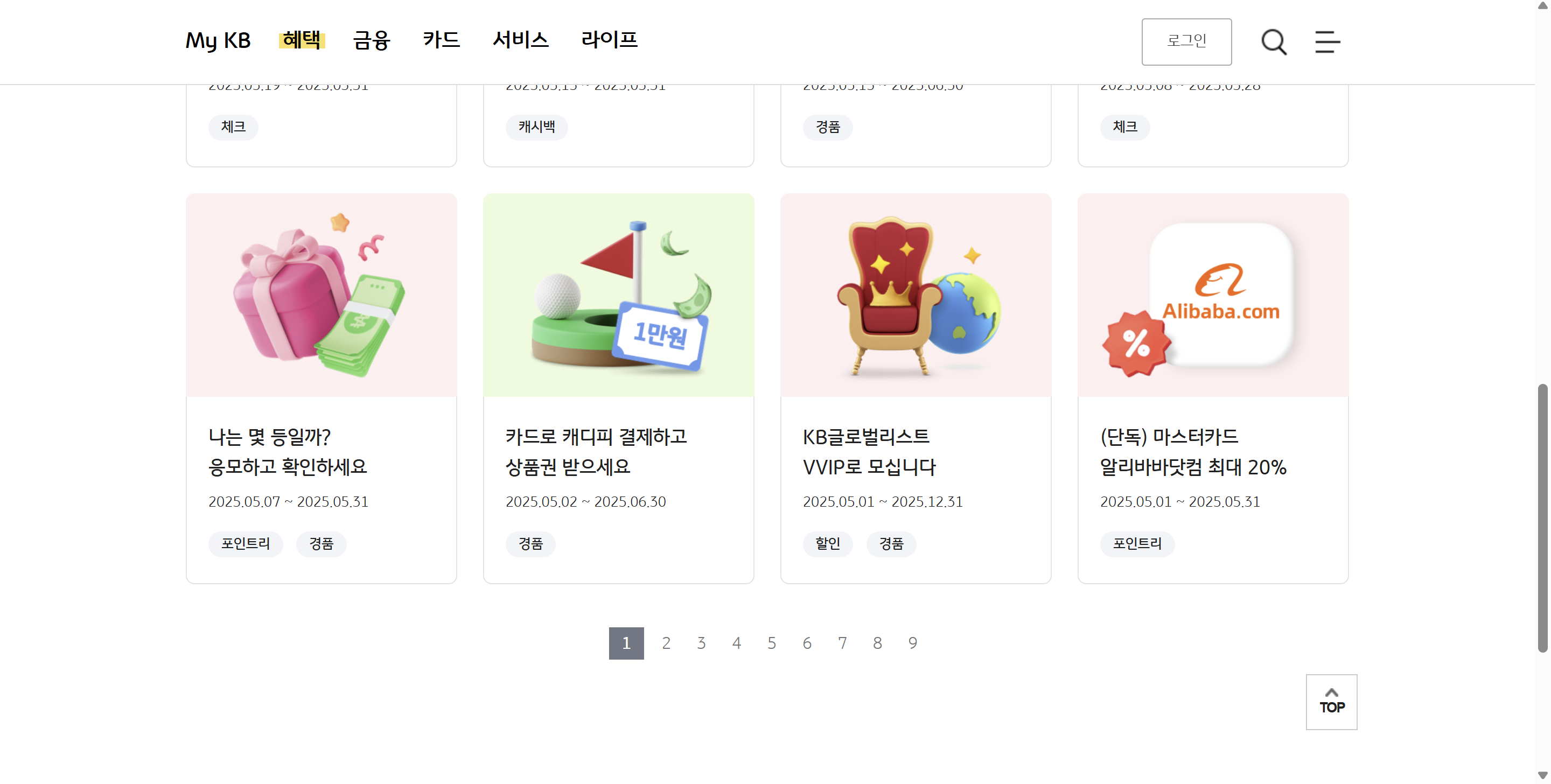
페이지네이션(Pagination) 기능을 활용하고 있어, 하단에 페이지를 선택할 수 있는 버튼을 포함하고 있습니다.
각 이벤트 정보는 다음과 같은 형태로 구성되어 있습니다.
<ul class="eventList">
<!-- loop -->
<li>
<a href="javascript:goDetail('이벤트코드', '', '1');">
<span class="thumb" style="background-color:#FFF1E9">
<!-- admin에서 적용한 컬러 적용 -->
<img src="이미지링크" alt="아고다">
</span>
<div class="evtlist-desc">
<span class="subject">아고다<br>최대 15% 즉시할인</span>
<span class="date">2025.05.19 ~ 2025.09.30</span>
<span class="category">
<!-- 태그값이 없을 경우 dom전체 삭제 -->
<em class="sale">할인</em>
</span>
</div>
</a>
</li>
<!-- loop -->
<li></li>
# ...반복
<ul>안에 여러 개의 <li>가 포함되어 있고 각 <li>에는 각 이벤트의 간단한 정보와 상세 페이지 링크가 포함되어 있습니다. (javascript 함수 호출 형태)
여기서 각 <li>에 들어있는 정보를 수집하여 csv 형태로 저장하고자 합니다.
href에 있는 이벤트 코드img의srcclass="evtlist-desc"인element속 subject 텍스트class="evtlist-desc"인element속 date 텍스트class="category"인element속<em>카테고리
우선 각 이벤트의 정보를 배열로 저장하기 위해 변수를 설정합니다. 이 내용은 이후 .csv 파일에 저장합니다.
event_codes = []
event_images = []
event_subjects = []
event_start = []
event_end = []
event_categories = []
BeautifulSoup를 사용합니다. BeautifulSoup은 HTML이나 XML 문서를 파싱해서, 원하는 데이터를 쉽게 추출할 수 있게 도와주는 파이썬 라이브러리입니다.
html = urlopen('https://card.kbcard.com/BON/DVIEW/HBBMCXCRVNEC0001')
soup1 = BeautifulSoup(html, 'html.parser')
이렇게 BeautifulSoup로 HTML 파싱을 했습니다. 여기서 원하는 부분만 뽑아 쓸 것입니다. 우선 class = eventList인 <ul> 태그를 찾습습니다.
# 이벤트 항목 찾기
event_list = soup2.find('ul', {'class': 'eventList'})
그리고 <ul> 태그 속 각 <li>를 배열에 넣습니다.
if event_list:
event_items = event_list.find_all('li', recursive=False)
# 정보 가져오기
else:
print("❌ <ul class='eventList'>를 찾을 수 없습니다.")
이제 event_items는 <li> 태그를 저장하고 있는 배열이 됩니다. for문을 사용해 각 <li> 태그에서 원하는 정보를 가져옵니다. (아래 내용을 # 정보 가져오기에 넣습니다!)
for item in event_items:
a_tag = item.find('a')
if not a_tag:
continue
# 이벤트 고유 코드 추출
href = a_tag.get('href', '')
if "goDetail(" not in href:
continue
try:
code = href.split("goDetail('")[1].split("'")[0]
except IndexError:
code = ''
event_codes.append(code)
# 이미지 URL
img_tag = item.find('img')
img_src = img_tag['src'] if img_tag else ''
event_images.append(img_src)
# 제목
subject_tag = item.find('span', {'class': 'subject'})
subject = subject_tag.get_text(separator=' ', strip=True) if subject_tag else ''
event_subjects.append(subject)
# 날짜 → start_date / end_date
start_date, end_date = '', ''
date_tag = item.find('span', {'class': 'date'})
if date_tag:
date_text = date_tag.text.strip().replace(" ", "")
try:
start_str, end_str = date_text.split("~")
start_date = datetime.strptime(start_str, '%Y.%m.%d').strftime('%Y-%m-%d')
end_date = datetime.strptime(end_str, '%Y.%m.%d').strftime('%Y-%m-%d')
except ValueError:
pass
event_start.append(start_date)
event_end.append(end_date)
# 카테고리 (여러 개일 수 있음)
category_box = item.find('span', {'class': 'category'})
categories = []
if category_box:
for em in category_box.find_all('em'):
categories.append(em.text.strip())
event_categories.append(json.dumps(categories, ensure_ascii=False))
이렇게 반복문을 돌리면 추출한 정보가 각 event_codes, event_images, event_subjects, event_start, event_end, event_categories 배열에 순서대로 저장됩니다. 이제 이 내용을 .csv 파일에 저장할 것입니다.
# 결과 저장
data = {"event_code" : event_codes, "event_subject" : event_subjects, "event_image": event_images, "event_start": event_start, "event_end": event_end, "event_categories": event_categories}
df = pd.DataFrame(data)
df.to_csv("./KB_Kookmin_eventInfos.csv", encoding = "utf-8-sig")
이렇게 작성한 코드를 실행해보면 어떤 결과가 나올까요?
우리는 아직 해당 이벤트 페이지의 페이지네이션을 고려하지 않았습니다. 그래서 여기까지 작성한 코드를 실행하면 #1 페이지의 12개 이벤트만 저장하게 됩니다.
이어지는 페이지도 가져오기 위해 우선 웹사이트에서 어떤 방식으로 페이지를 전환하는지 확인합니다.
<div class="paging">
<div class="paging">
<a class="recentList" href="#" title="현재 선택됨">1</a>
<a href="javascript:doSearchSpider("HBBMCXCRVNEC0001","2")">2</a>
<a href="javascript:doSearchSpider("HBBMCXCRVNEC0001","3")">3</a>
<a href="javascript:doSearchSpider("HBBMCXCRVNEC0001","4")">4</a>
<a href="javascript:doSearchSpider("HBBMCXCRVNEC0001","5")">5</a>
<a href="javascript:doSearchSpider("HBBMCXCRVNEC0001","6")">6</a>
<a href="javascript:doSearchSpider("HBBMCXCRVNEC0001","7")">7</a>
<a href="javascript:doSearchSpider("HBBMCXCRVNEC0001","8")">8</a>
<a href="javascript:doSearchSpider("HBBMCXCRVNEC0001","9")">9</a>
</div>
</div>
위 HTML 코드를 보면 현재 1 페이지가 선택되었고, 2부터 9페이지는 javascript 함수 호출로 불러오는 것을 확인할 수 있습니다.
Selenium을 사용해서 각 페이지에 들어간 뒤 정보를 가져올 수 있도록 수정해야 합니다. Selenium은 웹 브라우저를 자동으로 제어할 수 있게 해주는 오픈소스 툴로, 이 경우와 같이 동적으로 만들어지는 웹 페이지에서 실제로 페이지 버튼을 클릭하는 것과 같은 동작을 할 수 있습니다.
그 전에 class = paging인 div에서 해당 페이지가 몇 개로 이루어져 있는지 가져옵니다.
# 총 페이지 수 찾기
paging_div = soup1.find('div', class_='paging')
page_links = paging_div.find_all('a', href=True)
이렇게 하면 page_links는 각 페이지 이동 버튼을 저장하는 배열이 됩니다. 여기서 배열의 길이는 총 페이지 수와 같습니다.
다음과 같이 webdriver를 import해주고
from selenium import webdriver
webdriver.Chrome()으로 url을 가져옵니다.
driver = webdriver.Chrome()
driver.get('https://card.kbcard.com/BON/DVIEW/HBBMCXCRVNEC0001')
마지막으로 각 페이지에 들어갈 수 있도록 아래와 같이 작성합니다.
for page in range(1, len(page_links) + 1):
# JavaScript 함수 호출
driver.execute_script(f'doSearchSpider("HBBMCXCRVNEC0001", "{page}")')
time.sleep(2) # 페이지 로딩 대기
soup2 = BeautifulSoup(driver.page_source, 'html.parser')
위 for문 안에서 event_list를 가져오고 각 event_item에서 정보를 가져오도록 수정하면, 각 이벤트에 대한 간단한 정보를 수집한 .csv 파일을 생성할 수 있습니다.
tags: crawling메인으로 돌아가기